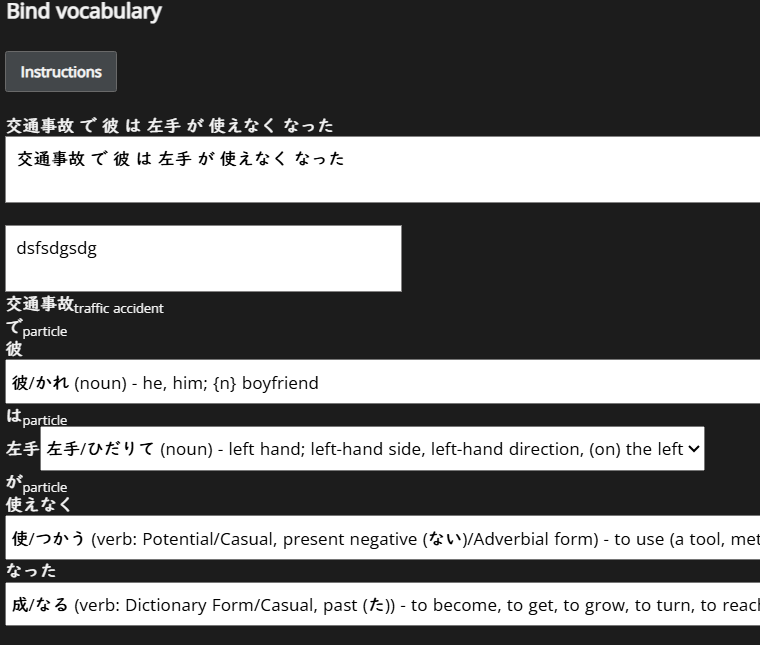
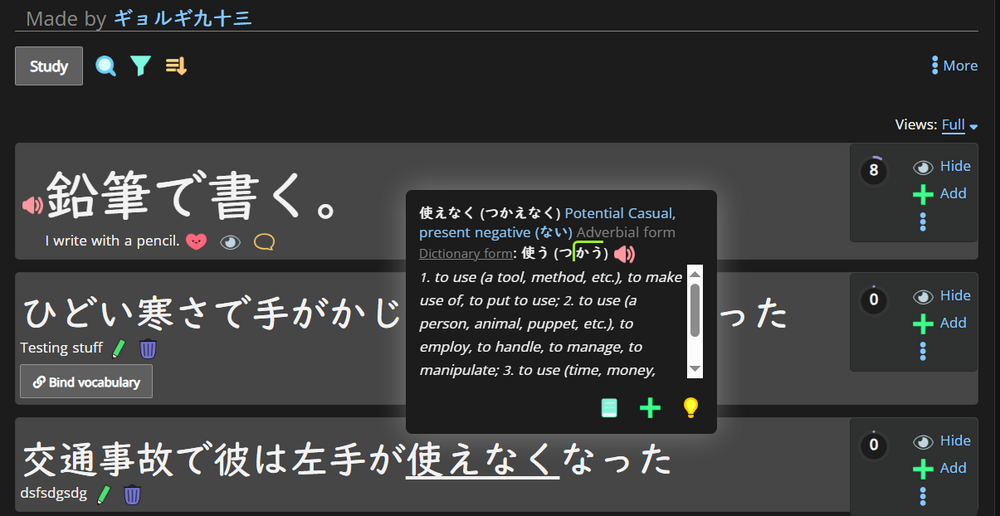
I don't think there's anything special about it, looks like a bug/error with the dictionary link. There's one sentence with 使えなくなる, and that seems to be split fine. It's the same thing, just なる instead of なった, right?
It's just the parsing tool struggling with long expression, I think. I had a similar problem with some casual sentences and it wasn't able to parse the sentences correctly. After asking マイコー if there was some kind of solution and the short answer was "no" (because of how the parsing tool works). Or maybe the problem was fixed but the sentence wasn't parsed again since that time.
Also, ギョルギ九十三, yeah but なった is not a unique token. The parser need to distinguish なった、なって、etc. And past a certain limit, it crash. Here 使えなくなった is probably decomposed like that: 使え + な+ く + な + った While 使えなくなる is probably decomposed like that: 使え + な + く + なる
Knowing that it had to that for the entire sentence. I don't the exact reason here but I guess it should be something like that. I think in my case, it was because of ~てる or ん (の) and too much て form. No matter what I tried and how I tweaked the sentences, it wasn't able to parse the sentences correctly. In the end I used [ ] to prevent the parsing tool to parse that part of the sentences as マイコー suggested. It was better than having an incorrect and confusing parsing.
It's just the parsing tool struggling with long expression, I think. I had a similar problem with some casual sentences and it wasn't able to parse the sentences correctly. After asking マイコー if there was some kind of solution and the short answer was "no" (because of how the parsing tool works). Or maybe the problem was fixed but the sentence wasn't parsed again since that time.
Also, ギョルギ九十三, yeah but なった is not a unique token. The parser need to distinguish なった、なって、etc. And past a certain limit, it crash. Here 使えなくなった is probably decomposed like that: 使え + な+ く + な + った While 使えなくなる is probably decomposed like that: 使え + な + く + なる
Knowing that it had to that for the entire sentence. I don't the exact reason here but I guess it should be something like that. I think in my case, it was because of ~てる or ん (の) and too much て form. No matter what I tried and how I tweaked the sentences, it wasn't able to parse the sentences correctly. In the end I used [ ] to prevent the parsing tool to parse that part of the sentences as マイコー suggested. It was better than having an incorrect and confusing parsing.
There's nothing wrong with the parser. It just needs to get reparsed manually.
I wonder how the parser works. it doesn't get handled on the client so I can't see the code. I don't know what Renshuu is using, but from a programming standpoint there shouldn't be any issues with distinguishing なった or なって. There's no reason for them to crash. In terms of computation, what you're describing is practically nothing.
It didn't crash, I'm just bad at english. But it couldn't get the correct parsing in some case. At least that was the issue at that time. It's was not a problem of computation but simply a problem of algorithm that couldn't work well in every case. In other words, depending on the rule you defined, it just made some bad conclusion in some particular case. That was the issue and why it couldn't be solved at that time.
Some of the major Japanese morphological/linguistic-analysis tools have had updates recently, so Renshuu's parser is likely better nowadays. Assuming it gets updated somewhat regularly. Mostly in terms of handling "contemporary spoken Japanese".
Also some literary forms. A few months ago it couldn't handle things like 黒き and 青き, but now it seems to handle them fine. It's also better with ~てる, ~んの, and ~て chains.
The problem you had might just be fixed at this point :)
PS: I was about to go on a long rant about dynamic programming algorithms, but then I realised I'm on a language learning forum... XD
PS: I was about to go on a long rant about dynamic programming algorithms, but then I realised I'm on a language learning forum... XD
Yeah, I saw that x) And I would not have argue on that part (I only studied text analysis)
But yeah, if it has been updated then nice. The main problem tho was more like a "technical debt" problem (at least partially). Like a lot of things on renshuu. But maybe マイコー found some solution for that one since then.