Is there any way to submit custom definitions for vocabulary via the API? If not, is there any possibility that that will be added? In the Swagger docs the only vocab endpoints I see are for adding / removing terms from schedules.
when using endpoint /schedule/{id}, the total_count seems to just be equal to studied_count, which may be less than the total number of terms in a deck if using a pre-made schedule deck
I think there should be a way to expose the true total number of terms in a schedule, as in the summation of all "Lessons in this schedule" terms
Which schedule is this? Lesson-based schedules are special, and they will NOT reflect correctly, as they are built in a state where the not-yet-studied lessons are not actually part of the schedule yet, and so they cannot be counted.
I tested on a few of the lesson-based schedules, such as on words for beginner japanese, so that is the issue, then. but it seems like there is still a general target summation number, for example for beginner japanese if you press the three dots and then press Lessons in this schedule, you will see (# of terms in parentheses) and if you all up all of those you will get the true total number. I just did a one time calculation by hand, so it's fine, I just think from a data perspective or smthin it might be nice having that actual total be returned somewhere by the API. but if the data structure doesnt fit outside of the lessons, thats of course fine.
I'll keep that in mind, but it would require significant changes to the code. I do not believe it would ideal to have the number suck in those "unloaded" lessons, but the term lists themselves still only show the ones that are currently active in the schedule. Adjusting it, then, to also have the list endpoints capture those terms would upend the way things are handled on the backend.
You're right. Maybe something like PUT/DELETE /kanji/{kanji}/{reading} ? Maybe that isn't enough because there are actually 4 states? Unknown, known, should be quizzed, and should not be quizzed.
Those are the same, more or less. It's a bit confusing.
Outside of user knowledge, there is, based on settings, a pool of readings you will be expected to know if you study a kanji.
Then, on the user side, there are only two data fields: known readings, and hide readings. Known = "I have studied this once, or studied a word in it (based on settings), etc." it is in some ways a subset of the pool of readings, but you can manually add readings to this pool.
On the flip side is hidden stuff. Those are the "regardless of if it is in the pool of readings to know or not, do not show/study this."
So as far as emulating the functionality that users have in the site/app, it's a binary toggle, but it may be moving things off of that null state of "haven't studied yet, so the user neither knows it nor has blocked it"
Thank you for having an API, this is really great. I struggle with learning terms when all the information is presented at once so I made a little helper app which you can use to study terms in a schedule one part at a time (definition/onyomi/kunyomi) before doing the quizzes on the Renshuu schedule . It's super janky, not complete but others might find it helpful since I have so far: https://powerfulbacon.github.i...
It is hosted on github.io so has no backend and does not send any data anywhere except Renshuu.
Hello, playing with the API. Thank you so much for making an API for Renshuu; it opens so many possibilites for studying across multiple platforms! I'm using it right now to scrape my browser history for JapanDict.com searches I make during my lessons and add them to a list in Renshuu that I can schedule for studying.
While I was adding new words to a list, I noticed what seems to be a bug in the `PUT /word/{word_id}?list_id={list_id}` endpoint, which showed up because of a bug in my own script. When I called that endpoint with a `word_id` that doesn't exist (in my case it was--oops--the uninterpolated text "{word_id}"), the endpoint still returned `200 OK`. I'd think that if no word exists at the path provided, it should be returning `404 Not Found`?
In my case, I set my script to run and stepped away for a moment, and I had run through all my daily API requests without actually adding any words because I kept trying to add a word ID that didn't exist but getting an OK status! Thanks for all your hard work on Renshuu. I love it!
While I was adding new words to a list, I noticed what seems to be a bug in the `PUT /word/{word_id}?list_id={list_id}` endpoint, which showed up because of a bug in my own script. When I called that endpoint with a `word_id` that doesn't exist (in my case it was--oops--the uninterpolated text "{word_id}"), the endpoint still returned `200 OK`. I'd think that if no word exists at the path provided, it should be returning `404 Not Found`?
200 OK means that the API received a valid request which was properly authed (authenticated) at the endpoint, it doesnt mean that there was a matching result. there are other types of response codes for more niche things like a 204), but for this type of API endpoint, 200 OK is the correct result. data validation should be handled on your (client) end. I am unable to check the result body from the 200 OK, but I just checked teh API spec for renshuu on swagger and it is interesting that 200 OK is just for "successfully added" so this is smthing that maybe should be looked into. technically it should still be 200 OK but that just means request received properly and then the return body contains something like a flag "successfully_added": false
if there isnt a response flag like that arleadya included in response payload u can just add all ur words and then make one list pull after for the entire list and then run a local diff check on returned words vs ur added ones and flag the ones that werent added is what id do. so just one extra API call at the end of ur adds.
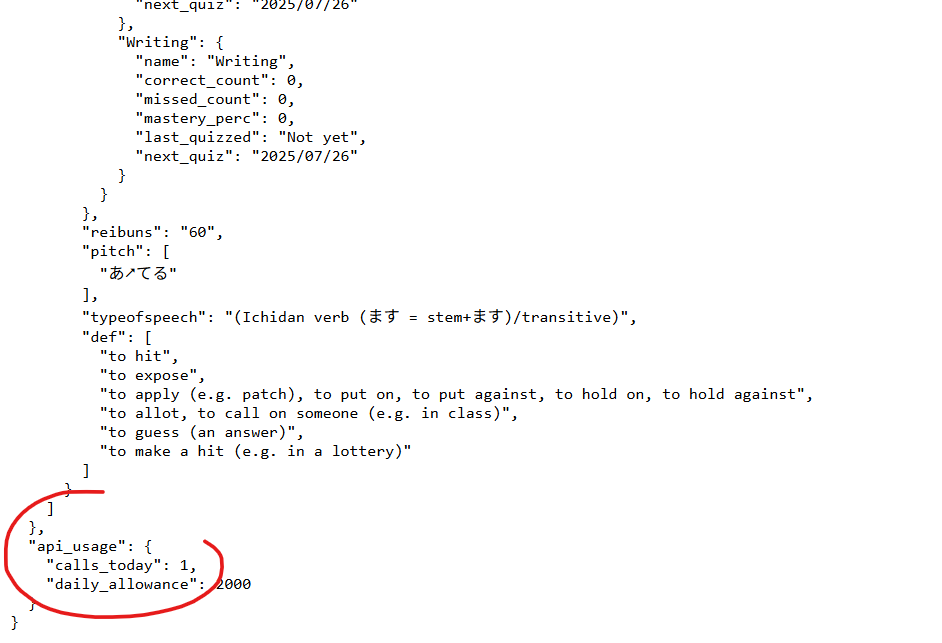
Hello, another API question! During testing I once accidentally got the API to return JSON to me telling me how many requests of my daily quota were remaining. Is there an endpoint that I can use to get that information, so I can inform users of my script where their quota stands?
Hello, another API question! During testing I once accidentally got the API to return JSON to me telling me how many requests of my daily quota were remaining. Is there an endpoint that I can use to get that information, so I can inform users of my script where their quota stands?
Pretty sure you get that with every request. It's at the "end":
That's what you're asking for right? I don't think there's a specific endpoint for it. I'm not 100% sure though.
There is not a standalone endpoint - I guess having one might be useful (so you don't burn a request as well as other server resources just to check that). What do you think?